When we write code it is often easy to get caught up in the implementation details. Communicating intent is imperative to making code understandable, and keeping code understandable is important for handling complexity.
Even if you don't practice DDD (or the problem space does not warrant it) and functional programming there are a few lessons to be learned from these disciplines that can be brought into any codebase.
Tip 1: Describe the workflow at your entry point
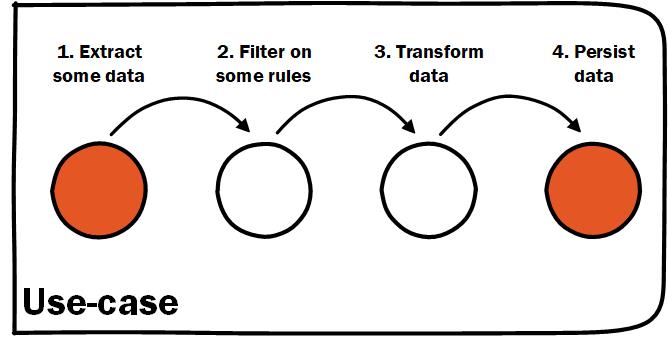
We have all heard the phrase "code is read many more times than it is written". What else is read a lot more than it is written? A book. Code is information dense and in any information dense book we have a Table of Contents. In your entry point to executing some use-case against your system it is important that there is a high-level workflow that gives an overview of the the complete use-case. This gives a developer reading from the entry point a "Table of Contents" to drill down into whatever step they need to.
In this context a workflow is the steps needed to do the work of the use-case. This entry point could be a controller or a program main. A pattern we use at work is to create a use-case specific class with a Do() or Execute() method on it. Play around with the naming though. I like the class to describe the use-case while the method that causes execution to say something about the command coming in as a parameter eg. new CalculateSomething().For(command.SomeNumber).
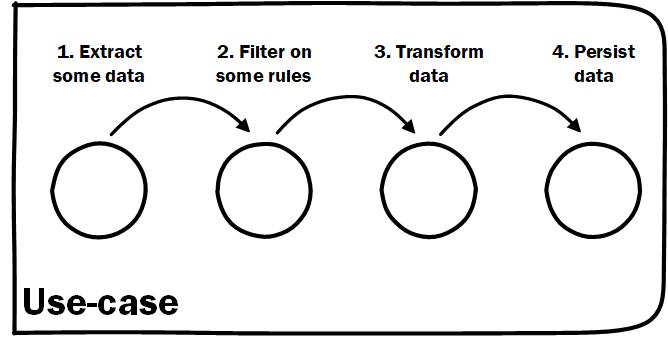
An easily understood use-case makes a great entry point for exploring a codebase
Inside the method on your use-case you should strive to lay out the code in the steps needed to complete that use-case. Try keep these steps at the same high-level of abstraction but not too high-level. What do I mean by too high? Be sure to describe actual meaningful steps that avoid steps that doing multiple things and all you can describe them is as ProcessX. If you find yourself naming a step like that it is probably worth breaking that step into smaller more meaningful steps within the use-case.
What you really want to avoid here is scattering the steps needed to complete a use-case throughout an object hierarchy.
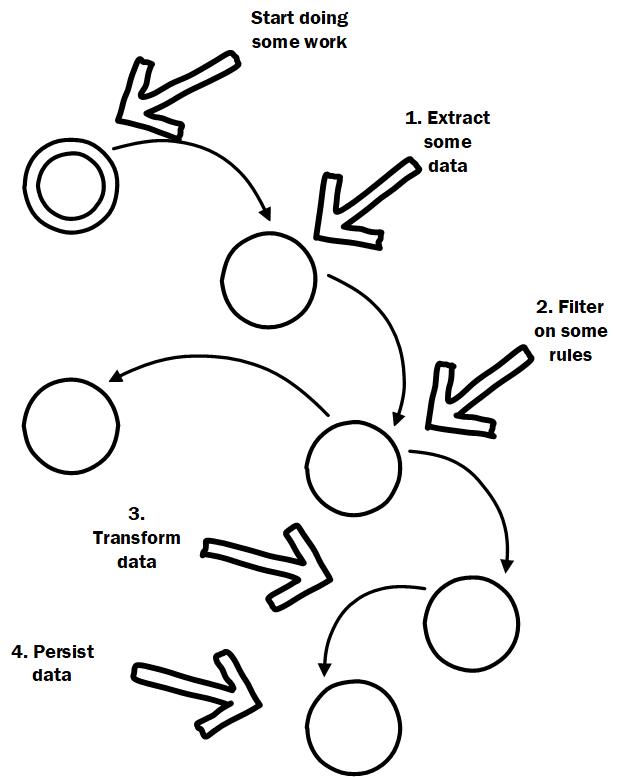
Sprinkling important application logic throughout a hierarchy makes it difficult to reason about
By spreading the workflow through the hierarchy it is really difficult to see at a glance what the workflow does and then drill down from there into how. It also makes it difficult to compose in new functionality. If it is within the hierarchy you will often find yourself putting code for new features in weird places because that is where the data is available in the call chain.
Tip 2: Prefer a longer workflow to a deep dependency chain
This one builds on the previous tip but where the previous tip focused on describing a workflow at the entry point, this one is more about cognitive load. Each step allows you to step into it and see the details. Each of these steps might itself have a few dependencies as well as mini-workflows captured in each of those dependencies. This is just a rule-of-thumb but if the depth of a single steps dependency hierarchy exceeds the width of the steps in a workflow, at least ask the question of whether that should maybe be 2 steps.
Why is this important? You do not want to have to dive very deep to understand what happens in a single step. Remember that the entry point gives a complete overview of all high-level steps. If a hierarchy is too deep if might become hard to reason about. This is of course just a rule-of-thumb and any single step could of course warrant a deep hierarchy to implement it well.
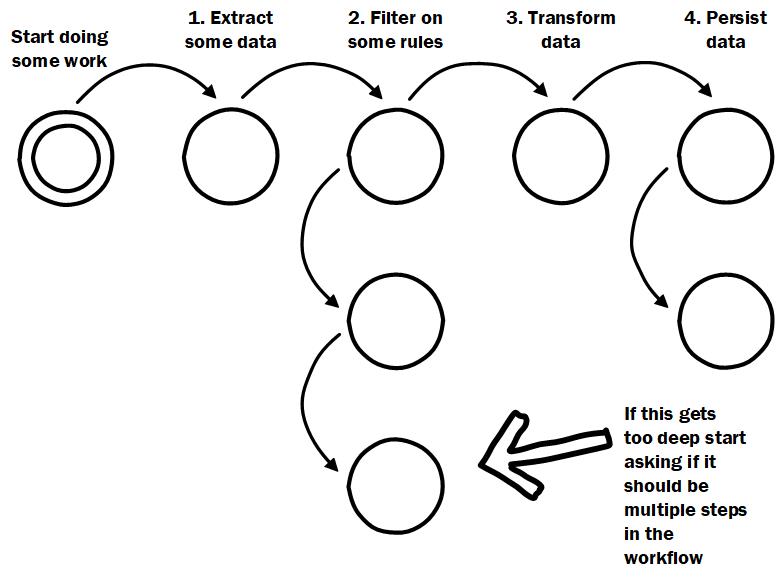
As a rule-of-thumb; keep your workflow longer than it is deep
Tip 3: Make your external dependencies visible
External dependencies like databases, files, and/or webservices make things difficult to reason about if they are nested deep in the dependency hierarchy where it is often unclear that they are being called. Not only that but it forces excessive use of abstractions purely for testing, which causes test induced damage to the code.
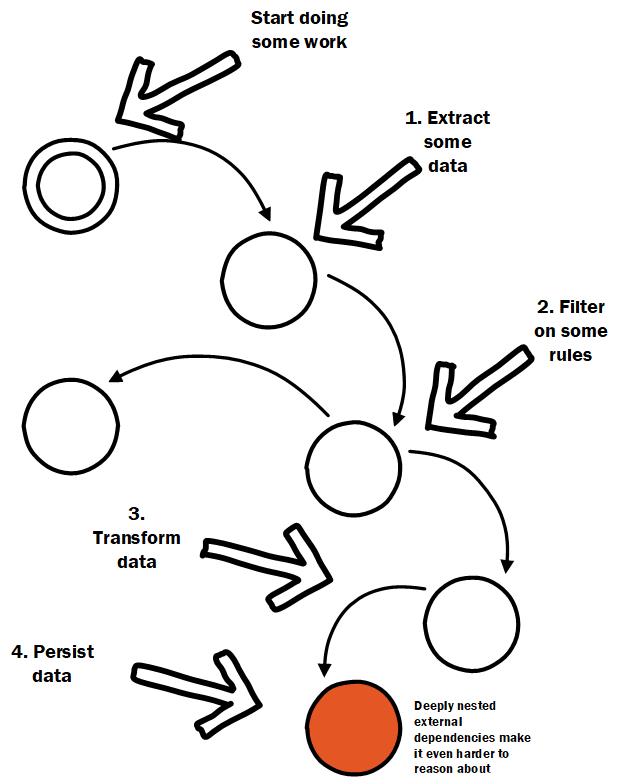
Deeply nested external dependencies make code more difficult to reason about and test
By making your external dependencies part of the high-level workflow you communicate the dependencies clearly. This makes it clear what is required for the system as a whole but also what data is needed to complete the use-case. This might mean thinking a little differently about the problem. Instead of querying for something the moment you need it, you might try fetch it at the start. You might say that seems wasteful as some validation might fail. That argument could be turned around though and it could be argued that there is no point in validating input if the external dependencies needed to complete a use-case are not available.
Make your external dependency calls clear in your high-level workflow
Tip 4: Push your external dependencies to the boundary
Obviously every use-case is different but if at all possible push your external dependencies to the beginning and the end of your workflow. This is taking a page out of functional programming where purity matters. What is meant by purity? Basically we strive to have all functions results be determined only by the value of the arguments passed in. This makes functions easy to reason about as well as easy to test.
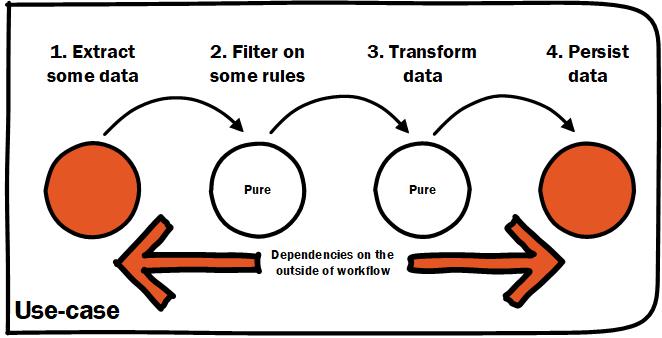
Calls to databases, files, and webservices should be pushed to the boundary of the workflow
I highly recommend watching From Dependency injection to dependency rejection by Mark Seemann to see a detailed discussion on the topic.
Tip 5: Bring business concepts up, push technical implementations down
Keep checking that you have important code that shows the details of business logic as close to the root of the object hierarchy as possible. The business logic is what developers should see first, while the implementation details are deep or at least on the boundary of the workflow.
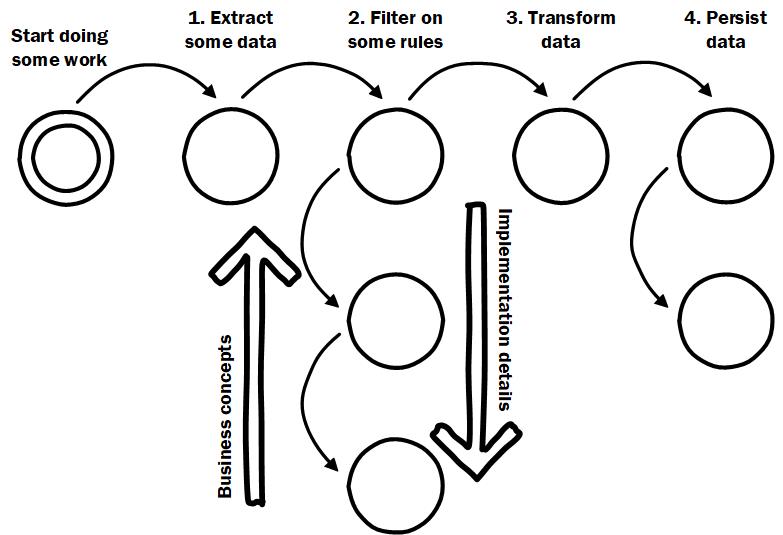
Favour business concepts further up the dependency hierarchy and implementation details lower down
Tip 6: Use abstraction judiciously
Abstractions are something you want at the seams of your application modules/components. Obviously you can use them elsewhere, certain design patterns call for them. The important thing is to use them where needed and not by default.
From a clean architecture point of view you would use them to implement Ports and Adapters as a nice way of keeping your domain logic clean of implementation details. Abstractions are part of your domain, implementations are specific and live in specific infrastructure dedicated to that implementation.
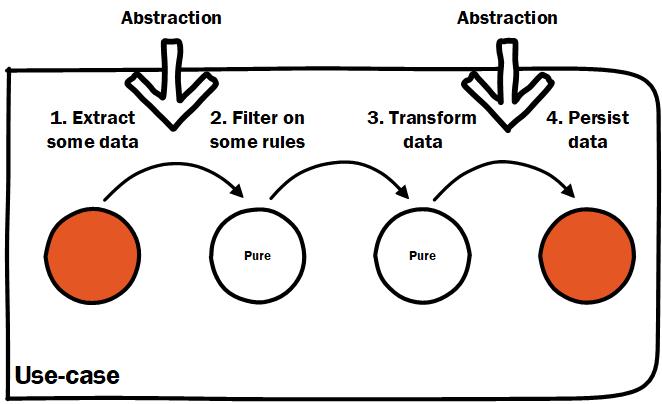
Place abstractions at the seams
Tip 7: Use honest rather than simple types
Create types to represent things like entity identity. There is a whole series on this but if you do nothing else don't let your codebase be littered with Guid, int, long, string or whatever else you use as entity identity or reference. When your code relies on invoiceId and invoiceLineId and etc. it becomes too easy to swap 2 integers. Not only does it help prevent silly bugs but using types a little more liberally can really help convey intent. Finally, it makes finding all references where a type is used simple.
And we are done
I hope you find some of these tips useful. If you did, I would love to hear about it. If you have questions, feel free to leave a comment. If you think I am 100% wrong, I would love to hear your reasons. Above all, let's keep learning together and happy coding!